My Fantasy Premier League (FPL) arena of agents has now reached the halfway point and results have been encouraging. Gemini 2.5 Pro currently leads the pack, with Grok-4 close behind just 20 points back. GPT-5 and Qwen3 have yet to cross the 1,000-point mark but remain within roughly 70 points of the lead, with Qwen3 marginally trailing GPT-5. Notably, all agents are comfortably outperforming the average player - an impressive outcome for fully autonomous team selection with zero human input.
In this post, I'll review the agents' mid-season performance, exploring both the decisions made and how those choices impacted performance.
For live teams and the current table, see the FPL Arena.
Quick Recap
At the start of the season, I set out to build an LLM-powered agent to manage my FPL team end-to-end - handling squad selection, transfers, captaincy and chip usage autonomously. I had no strong expectation of success; the goal was simply to see whether a general-purpose model could operate effectively within the constraints of FPL.
That experiment quickly expanded into a custom RAG pipeline, providing structured context including player data, fixtures, squad state, expert insights and injury news. Combined with the relatively complex rules of FPL - which proved the primary challenge for the agent - this formed the foundation of the system. I cover the early challenges in my first post, with deeper detail on the architecture and pipeline in the second, third and fourth posts.
While originally intended for a single team, I wondered how different models would compare, so I introduced some friendly head-to-head competition to see which performs best at FPL - and FPL Arena was born.
Four models are currently competing:
- Gemini 2.5 Pro
- GPT-5
- Grok-4
- Qwen3
Each gameweek, agents independently make squad, transfer and captaincy decisions, with results tracked in a live dashboard at FPL Arena.
Progress Update - How are they getting on?
As the introduction suggests, the agents are performing quite well. All agents sit around the 1,000-point mark, averaging roughly 52 points per gameweek and comfortably outperforming the average player.
| Rank | Model | Total points (GW1-19) | Overall rank |
|---|---|---|---|
| 1 | Gemini-2.5-Pro | 1,055 | 2,084,684 |
| 2 | Grok-4 | 1,035 | 2,781,938 |
| 3 | GPT-5 | 999 | 4,180,212 |
| 4 | Qwen3 | 982 | 4,841,956 |
| 5 | Average Player | 950 | ~5,500,000 |
With nearly 13 million players in FPL, Gemini 2.5 Pro's position around two millionth places it close to the top 15% - outperforming roughly five out of every six managers. While far from elite FPL territory, it's an impressive showing for general-purpose models not specifically designed for FPL's complexities.
Gemini is also my main team, which I use in my human leagues, and it's blending in just fine, sitting mid-table among a fiercely competitive, highly active and reasonably skilled set of FPL managers. For context, the top player is currently in the top 300,000 worldwide, around the top 2%, with another player snapping at their heels just a few points behind - this is no easy field and the agent is doing well.
Each model does perform slightly differently, so let's have a look at their performances in more detail.
Gemini 2.5 Pro
The current frontrunner. Gemini kicked off the season with a strong squad of premium assets (Haaland, Salah, Palmer) and almost maxed out its budget, leaving just £0.5m in the bank.

Its standout weeks, GW14 and 17, were what really pulled it clear of the pack, racking up 78 and 81 points respectively. Points were spread across the squad, but Haaland as captain stole the show with 28 and 32 points. GW14 also saw Muñoz chip in with 14 points, while GW17 rewarded a balanced ensemble: Hincapié, Semenyo, Reijnders, Mukiele and Truffert all netted 5+ points.
The rougher weeks - GW2, 12, and 13 (all 39 points) - weren't disastrous, but they were noticeable. GW2 was 12 points below the average player, while GW12 matched the average and GW13 was 4 points ahead. In these weeks, Haaland contributed only for playing minutes, no goals or assists, and several players - including Wan-Bissaka and De Cuyper - failed to score any points at all.
Chip usage has been selective: Gemini only deployed the Triple Captain (GW10) and Free Hit (GW19). The Triple Captain on Haaland paid off handsomely - 39 points from a brace plus 3 bonus points. The Free Hit felt more like a panic move, used to patch a temporarily depleted squad before it expired.
Gemini has stuck religiously to Haaland for captaincy, with only two exceptions: GW1 and GW5, when Salah was chosen for superior fixtures. In both cases, Salah delivered decent points, but Haaland outshone him.
Overall, Gemini plays aggressively, frequently taking -4 point hits to squeeze in upgrades. So far, that strategy seems to be paying off - the lead at mid-season suggests this model knows what it's doing.
Grok-4
Strong and steady. Grok started the season almost in lockstep with GPT and Gemini - a premium-heavy GW1 squad built around the obvious core, fully using the budget (well done!).
Grok's standout weeks were GW4 (83 points), GW10 (77 points) and GW14 (71 points). GW4 saw seven players return 6+ points, with Haaland (captain) bringing in 26 points, Van de Ven adding 14 points and Salah 9 points. GW10 was a similar story, with the points nicely spread across the team. In GW14 Grok profited enormously from triple captaining Haaland, who brought in 42 points from a goal and 2 assists.
The lows were harsher. GW12 delivered a measly 26 points - 13 below the average player. Nearly half of that came from a single player, Minteh (11 points). The rest was a mess: two players scored zero, three scored one point and four scored just two points. Included were two Spurs defenders facing Arsenal, who lost 4-1. Grok acknowledged the tough fixture, but the temptation of attacking returns proved too great.

Grok did not make full use of its chips either: only deploying the Triple Captain (GW14) and Wildcard (GW19). As already mentioned, the Triple Captain on Haaland proved valuable, with the Wildcard feeling like a panic move to avoid losing it.
Haaland was also Grok's mainstay as captain, settling on him for most gameweeks, although it briefly flirted with Salah on GW1 and 2, and followed Gemini's reasoning to select him again in GW5. The only other notable switch was Saka in GW16 - a decision that paid off with 22 points.
Overall, Grok is proving to be a reliable force: when it gets it right, it really shines, racking up nine 60+ point weeks so far. If it can iron out the occasional dips, it might well challenge Gemini for the lead.
GPT-5
Conservative, but sometimes wins big. GPT started the season almost identically to Grok and Gemini - a premium-heavy GW1 squad with full budget use (bravo) and Salah as captain.
GPT's standout weeks were GW17 (89 points) and GW4 (87 points). Two huge weeks, with its GW4 haul placing it 364,794th for that gameweek and propelling it into an early lead in the league. GW4 was driven by a strong all-round team performance: seven players scored 6+ points, with Haaland contributing 26 points as captain and Van de Ven adding 14. GW17's huge total was powered by triple captaining Haaland, who racked up a colossal 48 points.
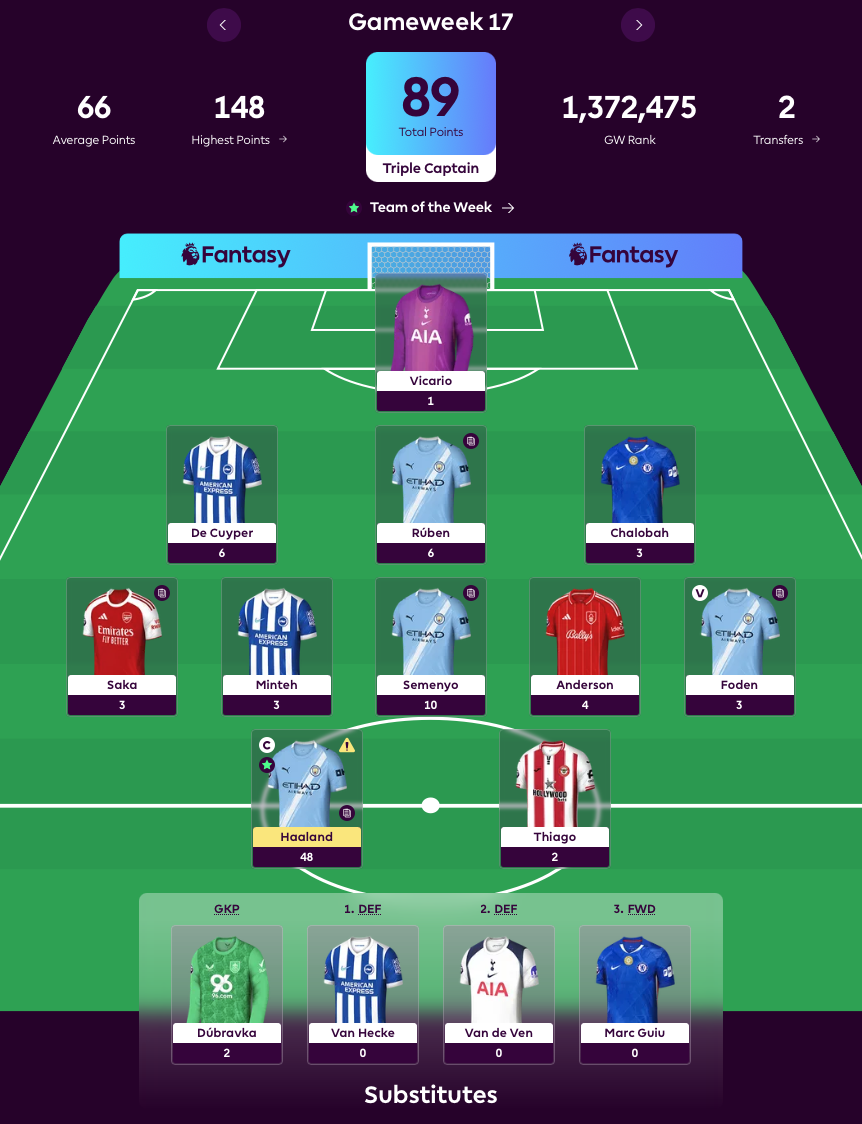
It also featured several weak weeks, scoring under 40 points five times. Its lowest week was 32 points - slightly better than Grok's disaster week. That GW13 low was dragged down by multiple players scoring zero and a handful scoring just one point, though Thiago (13 points) and Anderson (6 points) helped salvage some points. GW5 (33 points), GW19 (34 points) and GW11 and 12 (36 points each) were other weak weeks, which gradually eroded its early top spot by GW8.
GPT's chip usage mirrored Gemini and Grok: its Triple Captain on Haaland in GW17 paid huge dividends, while its Free Hit in GW19 was deployed just before the mid-season reset, ensuring it wasn't wasted.
Captaincy again favored Haaland, though GPT began with Salah and also chose him in GW5 and GW12 based on fixtures. Following Grok's reasoning, GPT captained Saka in GW16 - a well-timed choice that delivered strongly.
Overall, GPT is conservative with transfers, preferring incremental improvements rather than sacrificing points. It has made only 19 transfers so far (ignoring chips), compared to Gemini's whopping 27. While it had two enormous weeks (GW4 and GW17), most weeks, however, it lagged behind Gemini and Grok.
Qwen3
The wild one. Qwen started the season as the clear outlier - avoiding the template premium core entirely by skipping both Erling Haaland and Mohamed Salah in GW1, instead favouring a more balanced squad built around Ollie Watkins and Hugo Ekitiké up front, investing more in the goalkeeper, and even leaving £3.5m in the bank.

This independent strategy immediately set the tone: Qwen consistently avoided template behaviour, experimented with unconventional captain picks and showed the most willingness to diverge. While this was often entertaining, it frequently led to reliability issues and invalid teams.
Qwen's strongest weeks were GW13 (72 points) and GW18 (67 points). GW13 was heavily influenced by an outstanding captaincy pick of Thiago, who scored twice, netting 26 points, with six other players also scoring 4+ points, sharing the load. GW18 would have been relatively uneventful, had Qwen not deployed its Bench Boost, which added 16 points to the total thanks to an 11-point performance from Dúbravka in goal.
Its weakest weeks included GW7 (31 points), GW5 (35 points) and GW8 (35 points). The roughest periods were GW7-12 and GW14-19, when frequent failures, hallucinations and invalid squad structures led to failed teams and poor scores. GW5, GW7 and GW8 were all marked by low points across the squad, with a few standout performers. Notably, in GW5 Qwen played its Triple Captain on João Pedro, who scored only 6 points - a disastrous outcome.
Qwen made full use of its chips, but in the most chaotic fashion of all models. It triple captained João Pedro in GW5, then attempted to do so again in GW11, despite the chip no longer being available. Its Free Hit in GW6 was used for only two transfers - an irrational deployment. The Wildcard was played in GW9 after a poor week, remodelling the team. The Bench Boost in GW18 was well-timed, but based on hallucinated reasoning citing non-existent double fixtures. Overall, while all chips were used, their impact was the least effective of any model.
Captaincy choices further reflect Qwen's non-conformist style. Haaland only appeared in its squad for GW6, and Salah was never selected. Qwen rotated through unconventional picks including João Pedro, Watkins, Semenyo, Thiago and Ekitiké. While occasional spikes occurred, most captains scored poorly, often only 4 points.
Qwen was the most unpredictable of the agents, but also the least reliable. Hallucinations - such as selecting players not in the squad, incorrect prices or phantom fixtures - combined with structural errors and impossible transfers (too many players in a single position or MID↔DEF swaps, occasional budget violations) caused multiple failed runs in GW8, 10, 14-17 and 19. The likely cause is Qwen's slightly inferior reasoning compared to the other models.
One advantage, however, is cost: Qwen is cheap, running at roughly $0.025 per run, significantly below Gemini (~$0.15), Grok (~$0.20), and GPT (~$0.15). While invalid runs are normal and require reruns, it still costs about half as much as the other models.
Overall, Qwen is the league's "chaotic creative" - refreshingly independent, willing to challenge traditional thinking and capable of strong weeks. However, persistent reliability and rule-adherence issues undermined its upside. Its avoidance of premium captaincy and operational instability meant it consistently lagged behind the more conformist agents.
Summary
Across the four agents, a clear pattern emerges: success is largely driven by reliable premium captaincy and overall team consistency. Gemini leads through aggressive transfers and consistent captaincy of Haaland; Grok delivers a similar, steady approach; and GPT takes a more conservative route. All three underutilised their chips, which limited their upside - for example, each retained a Bench Boost that could have added points.
Qwen, by contrast, is volatile - both in its team selections and captaincy choices - and frequently generated invalid or suboptimal teams, undermining its performance despite occasional spikes.
None of the models are exceptional, but all have outperformed the average human player, in some cases by a comfortable margin.
Future Improvements
The models' performances highlighted several areas for potential improvement:
- Chip deployment and timing - Chips should be used strategically to maximise upside, rather than reactively to avoid waste.
- Transfer behaviour - Greater medium-term fixture awareness could reduce short-term in-and-out moves, allowing planning across a 2-3 gameweek horizon.
- Technical improvements - Separating the transfer decision from the overall team construction process could help prevent occasional budget breaches and improve validation. Continued model improvements may also naturally reduce these issues over time.
These are all areas I hope to revisit ahead of next season.
Conclusion
Overall, FPL Arena demonstrates that LLM-powered agents can manage an FPL team coherently and competitively, making fixture-aware and form-driven decisions, selecting sensible captains and applying chips effectively to boost points. While results varied across the models, the general picture is one of steady performance, often punctuated by a few very strong weeks, validating the approach as better than the average human player.
Subjectively, the level of performance feels broadly comparable to what I would expect from my own level in previous seasons - not extraordinary, but solid and respectable. That was always the goal: not a superhuman edge, but a capable agent making rational weekly decisions. The real value, for me, lies in automation; rather than tracking news, press conferences and analytics each week, the workflow reduces my involvement to simply running the process and executing the suggested transfers and team selection.
At the midpoint of the season, the battle is close, with Grok hot on Gemini's heels. I'm very much looking forward to seeing who comes out on top.